Наконец-то очередная статья на тему настройки QoS на 2960/3560/3750! Теперь поговорим об очередизации трафика.
В отличии от коммутаторов-предшественников 2950/3550, на новых моделях к исходящим очередям добавились еще и входящие, и принципиально поменялся алгоритм работы исходящих очередей – теперь это SRR (Shaped Round Robin). В каждой из исходящих очередей есть 3 порога сброса (2 из которых можно двигать). Одна из 4-х исходящих очередей на порту – приоритетная (теперь это очередь номер 1). Таким образом, возможности QoS на этой серии коммутаторов кодируются как 1P3Q3T (1 приоритетная очередь, 3 карусельных, по 3 порога сброса в каждой из карусельных очередей). Появилась возможность тонкой настройки буферов во входящих и исходящих очередях.
Настройка исходящих очередей на коммутаторах 2960/3560/3750
Итак, даже если мы имеем коммутатор — быстрый, как американский хайвей, с полностью неблокируемой матрицей, у нас есть возможность поиметь затык (по-научному — переполнение) на исходящем интерфейсе, и огрести соответствующие проблемы в виде исключительно плохого качества голоса и видео, а также проседания прочих весьма полезных приложений. Но у нас есть Shaped Round Robin! Да здравствует управляемая несправедливость! Даешь деление полосы пропускания интерфейса между очередями в соответствии с приоритетом трафика! Отсутствует трафик в одной из очередей – полоса делится в заданных пропорциях между теми очередями, которым она нужнее (режим Shared). А будет у нас плохое настроение – вообще ограничим полосу пропускания какой-либо из очередей, чтобы не выпендривалась (режим Shaped). Тогда трафик этой очереди не сможет превысить планку, даже если есть свободная полоса.
Пороги сброса нужны для того, чтобы начинать сбрасывать трафик при достижении какого-то уровня заполнения очереди. А несколько порогов сброса нужны для реализации дифференцированного сброса. Он проявляется в том, что разные маркировки страдают по-разному сбрасываются на разных порогах. Надо только определить, кто на каком пороге должен «страдать» 🙂 Получается следующая картинка:

Помните, в предыдущей статье мы говорили, что в качестве внутренней маркировки в этих моделях используется QoS Label, которая может формироваться из входящего DSCP или CoS? И та же самая «КОСовская метка» используется как для назначения трафика на так и на исходящие очереди, так и на пороги сброса в исходящих очередях, причем все это делается одной и той же командой:
Switch(config)# mls qos srr-queue output dscp-map queue queue-id threshold threshold-id dscp1…dscp8
или
Switch(config)# mls qos srr-queue output cos-map queue queue-id threshold threshold-id cos1…cos8
например,
Switch(config)# mls qos srr-queue output dscp-map queue 1 threshold 2 10 11
Это означает, что трафик с DSCP 10 и 11 должен попадать в первую очередь и сбрасываться на втором пороге сброса.
ОК, трафик рассажен по очередям и по порогам сброса, теперь настроим режим Shaped – ограничение полосы пропускания в определенной очереди/очередях, даже если в соседних очередях есть незанятая полоса пропускания. Это делается командой:
Switch(config-if)# srr-queue bandwidth shape weight1 weight2 weight3 weight4
например
Switch(config-if)# srr-queue bandwidth shape 25 0 0 0
Это означает, что первая очередь ограничивается до 1/25 = 4% от интерфейсной полосы пропускания (не спрашивайте меня, почему сделали именно так), а остальные 3 – не поверите! работают в режиме Shared! И отдельной командой настраиваются весовые коэффициенты деления полосы пропускания в режиме Shared:
Switch(config-if)# srr-queue bandwidth share weight1 weight2 weight3 weight4
например
Switch(config-if)# srr-queue bandwidth share 30 20 25 25
При том, что 1-я очередь уже настроена в режиме Shaped, деление полосы пропускания между 2-й, 3-й, 4-й очередями считается так:
2-я: 20/(20+25+25)=28.6%
3-я: 25/(20+25+25)=35.7%
4-я: 25/(20+25+25)=35.7%
Команда srr-queue bandwidth shape имеет более высокий приоритет, чем srr-queue bandwidth share. В этом примере в команде srr-queue bandwidth share цифра 30 просто не учитывается.
Абсолютный приоритет для очереди номер 1 (что будет весьма пользительно для голоса, видео и другого real-time трафика) настраивается так:
Switch(config-if)# priority-queue out
Настройка буферов на исходящих очередях
На коммутаторах этих моделей можно настроить пропорции распределения буферной памяти между очередями 1, 2, 3, 4, а также двигать пороги сброса (двигать можно 1-й и 2-й, а третий порог двигать нельзя, он всегда 100% — это край очереди).
Настраивается это все хозяйство на уровне Queue Set – это некий шаблон, который потом назначается на интерфейс. Создать можно максимум 2 шаблона – номер 1 и номер 2.
Switch(config)# mls qos queue-set output qset-id buffers allocation1 … allocation4
Switch(config)# mls qos queue-set output qset-id threshold queue-id drop-threshold1 drop-threshold2 reserved-threshold maximum-threshold
Switch(config)# interface interface-id
Switch(config-if)# queue-set qset-id
Например:
Switch(config)# mls qos queue-set output 2 buffers 40 20 20 20
Switch(config)# mls qos queue-set output 2 threshold 2 40 60 50 200
Switch(config)# interface gigabitethernet0/1
lSwitch(config-if)# queue-set 2
Мы только что создали шаблон 2, который повесили на interface gigabitethernet0/1. Первая команда в примере задает проценты деления буферной емкости между очередями:
1-я очередь — 40%,
2-я очередь — 20%,
3-я очередь — 20%,
4-я очередь — 20%.
Вторая команда определяет для очереди номер 2 первый порог как 40% от длины очереди, второй порог – как 60% от длины очереди. Третий порог не двигается и равен 100%. Следующее число – изменение «зарезервированного» порога, а четвертый – «максимальный» порог. Что за числа такие?
Представьте себе общество, в котором у каждого есть некий минимальный объем ресурсов, который гарантирован при любых обстоятельствах. И есть «общак», из которого мы можем брать дополнительные ресурсы, если нам не хватает. Из «общака» берем по принципу «кто первый встал, того и тапки», то есть если весь «общак» уже раздербанили, и нам не хватило, то мы опоздали. И чтобы этот «общак» кто-нибудь один не захапал, есть максимальный порог объема ресурсов, который можно взять из «общака».
Итак, на каждом порту коммутатора у каждой из четырех очередей есть минимальный объем буферной памяти, которая гарантирована данной очереди конкретного порта. На хватает буферов – никто не мешает пойти и попросить из «общака». Но – не больше, чем максимальный порог (больше просто не дадут – например, не больше трех товаров в одни руки, надо же все-таки и совесть иметь!), и при условии, что в общаке хоть что-то осталось.

Как понять, какие проценты там указывать? Логика заключена в относительности величин. Например, по умолчанию минимальный порог 100%. Зададим 50% – значит, отказываемся от половины наших гарантий в пользу «общака». Зададим 200% – увеличим наши гарантии в 2 раза. Зададим максимальный порог 400% – значит, потенциально можем захапать в 4 раза больше, чем минимальные гарантии (если дадут, конечно). В вышеприведенном примере для второй очереди первый порог – 40%, второй порог – 60%, третий какой? Правильно, 100%! Далее в команде – резерв 50% (тут надо знать, что было по умолчанию, если 100%, значит отказались от половины резерва в пользу «общака»). И максимально захапать можем в 4 раза больше, чем резерв.
Вот таблица с параметрами по умолчанию для исходящих очередей:

Настройка входящих очередей на коммутаторах 2960/3560/3750
Опустим холивар на тему, для чего нужны входящие очереди, и скажем, что очередей всего две. Режим – только Sharing. Можно указать одну из очередей как приоритетную. Но приоритезация здесь работает по-особому: сначала обслуживается очередь, продекларированная как приоритетная, например, до 10% полосы пропускания. А оставшиеся 90% полосы делятся между обоими очередями в пропорции, задающейся весовыми коэффициентами. Девиз – «сначала мы твое съедим (впрочем, не полностью), а потом каждый свое будет есть». Нужно задать эти самые весовые коэффициенты, то есть в каких пропорциях «каждый свое будет есть». Еще во входящих очередях есть по 2 порога сброса в каждой очереди, оба по умолчанию равны 100%.
Команды назначения фреймов на входящие очереди (назначение — по QoS Label – CoS или DSCP) – такие же, как и для входящих очередей, только вместо output пишем input.
Switch(config)# mls qos srr-queue input dscp-map queue 1 threshold 1 0 1 2 3 4 5 6
Switch(config)# mls qos srr-queue input dscp-map queue 1 threshold 2 20 21 22 23 24 25 26
Конфигурим сами пороги (например, для очереди номер 1):
Switch(config)# mls qos srr-queue input threshold 1 50 70
Распределяем буфера между входящими очередями (первой — 60%, второй — 40%):
Switch(config)# mls qos srr-queue input buffers 60 40
Далее конфигурим приоритезацию и весовые коэффициенты:
Switch(config)# mls qos srr-queue input priority-queue 1 bandwidth 10
Switch(config)# mls qos srr-queue input bandwidth 4 4
Первая команда означает, что очередь номер 1 — приоритетная, ей гарантировано 10% от полосы пропускания входящего интерфейса, а оставшиеся 90% делятся поровну между первой и второй очередями (поровну — потому, что весовые коэффициенты 4 и 4 — они равны). То есть первая очередь получит 10% + 45% = 55% интерфейсной полосы, а второй достанется 45%. Первая очередь будет обслуживаться до тех пор, пока не выжрет свои 10% гарантированной полосы (чтобы была низкая задержка трафика real-time), а потом будет карусельная обработка между первой и второй очередями.
Если в первой команде поставить нуль, это означает, что мы запрещаем приоритезацию в этой очереди:
Switch(config)# mls qos srr-queue input priority-queue 2 bandwidth 0
Вот таблица с параметрами по умолчанию для входящих очередей:

Настройка ограничения скорости на исходящем порту
Иногда есть необходимость ограничить скорость на исходящем интерфейсе — одеть на него ограничивающий «хомут». Делается это следующей командой:
Switch(config)# interface gigabitethernet0/1
Switch(config-if)# srr-queue bandwidth limit 80
Диапазон возможных значений — от 10 до 90, показывает, сколько процентов от скорости исходящего интерфейса должно быть доступно.
Последовательность операций
Ну и напоследок — 2 блок-схемы, отображающие последовательность операций на входящем порту коммутатора:
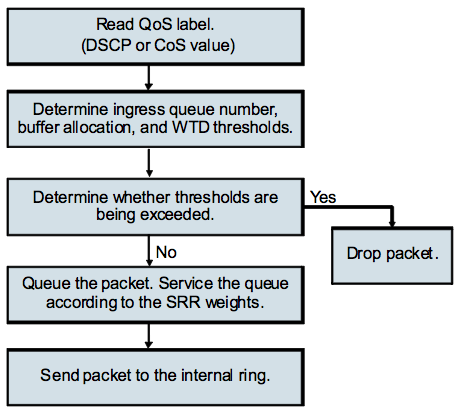
… и исходящем порту коммутатора:
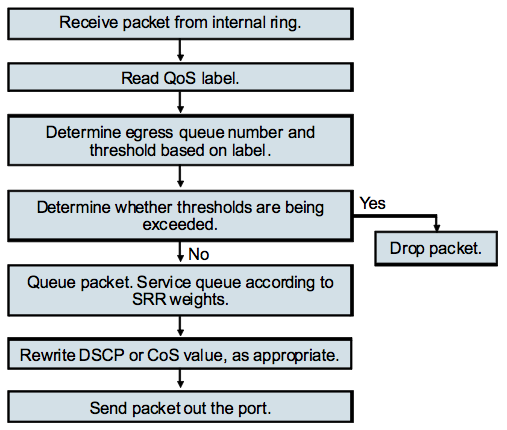
Дорогие коллеги, как говорится, не переключайтесь 🙂 скоро следующая статья про полисинг и шейпинг на 2960/3560/3750.
Вернуться в начало цикла статей по QoS на 2960/3560/3750.
--
С уважением,
Евгений Киселев aka Stratosphere

Метки: 2960, 3560, 3750, QoS, качество обслуживания, коммутаторы
Опубликовано: Маршрутизаторы и коммутаторы

Жень, личная просьба: обрежь статью для главной страницы (тэг «More —>»)
О, Сереж, пардон, совсем забыл про эту обрезку.
Сделал.
Благодарю за статью! Пишите еще! 🙂
Спасибо! обязательно буду писать!
Как всегда на высоте. Отменная статья. Благодарствую.
Вот интересно как много народу спускается до такого тонкого тюнинга как L2 QoS.
Красиво на словах, но настройки очередей не могут полностью избавить от дропов:
3750me#sh int fast 1/0/1
FastEthernet1/0/1 is up, line protocol is up (connected)
Hardware is Fast Ethernet, address is 0019.6082.e2c1 (bia 0019.6082.e2c1)
Description: 100Mbps, inet
MTU 1998 bytes, BW 100000 Kbit, DLY 100 usec,
reliability 255/255, txload 95/255, rxload 20/255
Encapsulation ARPA, loopback not set
Keepalive not set
Full-duplex, 100Mb/s, media type is 10/100BaseTX
input flow-control is off, output flow-control is unsupported
ARP type: ARPA, ARP Timeout 04:00:00
Last input never, output never, output hang never
Last clearing of «show interface» counters never
Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 452285394
Queueing strategy: fifo
Output queue: 0/4096 (size/max)
30 second input rate 8032000 bits/sec, 3565 packets/sec
30 second output rate 37514000 bits/sec, 5167 packets/sec
32026946800 packets input, 13406208556049 bytes, 0 no buffer
Received 9073264 broadcasts (0 IP multicasts)
0 runts, 0 giants, 0 throttles
32037 input errors, 32037 CRC, 0 frame, 0 overrun, 0 ignored
0 watchdog, 9046727 multicast, 0 pause input
0 input packets with dribble condition detected
49960545188 packets output, 43284144020560 bytes, 0 underruns
0 output errors, 0 collisions, 0 interface resets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier, 0 PAUSE output
0 output buffer failures, 0 output buffers swapped out
*************************
3750me#sh int fast 1/0/1
FastEthernet1/0/1 is up, line protocol is up (connected)
Hardware is Fast Ethernet, address is 0019.6082.e2c1 (bia 0019.6082.e2c1)
Description: 100Mbps, inet
MTU 1998 bytes, BW 100000 Kbit, DLY 100 usec,
reliability 255/255, txload 96/255, rxload 14/255
Encapsulation ARPA, loopback not set
Keepalive not set
Full-duplex, 100Mb/s, media type is 10/100BaseTX
input flow-control is off, output flow-control is unsupported
ARP type: ARPA, ARP Timeout 04:00:00
Last input never, output never, output hang never
Last clearing of «show interface» counters never
Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 452285700
Queueing strategy: fifo
Output queue: 0/4096 (size/max)
30 second input rate 5819000 bits/sec, 3173 packets/sec
30 second output rate 37717000 bits/sec, 4972 packets/sec
32027928179 packets input, 13406491358807 bytes, 0 no buffer
Received 9073270 broadcasts (0 IP multicasts)
0 runts, 0 giants, 0 throttles
32037 input errors, 32037 CRC, 0 frame, 0 overrun, 0 ignored
0 watchdog, 9046733 multicast, 0 pause input
0 input packets with dribble condition detected
49962124797 packets output, 43285662408104 bytes, 0 underruns
0 output errors, 0 collisions, 0 interface resets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier, 0 PAUSE output
0 output buffer failures, 0 output buffers swapped out
*************************
Queueset: 1
Queue : 1 2 3 4
———————————————-
buffers : 0 100 0 0
threshold1: 100 3100 100 100
threshold2: 100 3100 100 100
reserved : 50 100 50 50
maximum : 400 3200 400 400
*************************
interface FastEthernet1/0/1
description 100Mbps, inet
no switchport
no ip address
load-interval 30
no keepalive
speed 100
duplex full
srr-queue bandwidth share 25 255 25 25
xconnect encapsulation mpls
backup peer
hold-queue 4096 out
end
******************************
3750me#sh platform port-asic stats drop fast 1/0/1
Interface Fa1/0/1 TxQueue Drop Statistics
Queue 0
Weight 0 Frames 0
Weight 1 Frames 0
Weight 2 Frames 0
Queue 1
Weight 0 Frames 452009123
Weight 1 Frames 1377
Weight 2 Frames 0
Queue 2
Weight 0 Frames 0
Weight 1 Frames 0
Weight 2 Frames 0
Queue 3
Weight 0 Frames 0
Weight 1 Frames 0
Weight 2 Frames 0
3750me#sh mls qos
QoS is enabled
QoS ip packet dscp rewrite is disabled
3750me#sh ver
Cisco IOS Software, C3750ME Software (C3750ME-I5-M), Version 12.2(46)SE, RELEASE SOFTWARE (fc2)
К сожалению да, проблемы с дропами имеют место быть. Попробуйте покурить вот это: http://www.cisco.com/c/en/us/support/docs/switches/catalyst-3750-series-switches/116089-technote-switches-output-drops-qos-00.html мне помогло 🙂
> Switch(config-if)# srr-queue bandwidth share 30 20 25 25
> При том, что 1-я очередь уже настроена в режиме Shaped, деление полосы пропускания между 2-й, 3-й, 4-й очередями считается так:
Небольшая поправка: согласно документации, для режима shared считается не полоса пропускания, а частота, с которой планировщик отправляет пакеты из очередей, при этом используется вся свободная полоса пропускания, вплоть до 100%.